math
Introduction
math is a CHICKEN port of racket's math library.
The following documentation is largely a direct copy of the racket documentation, re-formatted for svnwiki and tweaked for the CHICKEN implementation.
Development status
This egg is still largely under active development. There may be missing modules and features.
Implementation caveats
- It's possible some undefined behavior may occur with arguments of the wrong type, since a good amount of the original functions were originally defined in typed racket, which AFAIK would catch those and throw an exception.
- In some places the original implementation references unsafe- fx and fl operators, but these are actually just aliased to safe operators. This implementation just uses CHICKEN's chicken.fixnum module, which is unsafe. This may also lead to undefined behavior in some cases.
Modules
(math base)
Constants and elementary functions
Note: This is currently missing procedures from racket/math that the original racket library re-exports.
Constants
[constant] phi.0An approximation of φ, the golden ratio.
> phi.0 1.618033988749895[constant] euler.0
An approximation of e, or Euler's number.
> euler.0
2.718281828459045
> (exp 1)
2.718281828459045[constant] catalan.0
An approximation of G, or Catalan's constant.
> catalan.0 0.915965594177219
Functions
[procedure] (float-complex? v) -> boolean- v
- any
Returns #t when v is an inexact complex number. Analogous to flonum?.
[procedure] (number->float-complex x) -> cplxnum- x
- number
Returns a new complex number with a flonum real part and a flonum imaginary part. Analogous to exact->inexact.
[procedure] (power-of-two? x) -> boolean- x
- number
Returns #t when x is an integer power of 2.
Examples:
> (power-of-two? 1.0) #t > (power-of-two? 1/2) #t > (power-of-two? (fpnext 2.0)) #f[procedure] (asinh z) -> number
[procedure] (acosh z) -> number
[procedure] (atanh z) -> number
- z
- number
The inverses of sinh, cosh, and tanh.
[procedure] (sum xs) -> number- xs
- (list-of number)
Like (apply + xs), but incurs rounding error only once when adding inexact numbers. (In fact, the inexact numbers in xs are summed separately using fpsum).
Random Number Generation
[procedure] (random-natural k) -> integer- k
- integer
Returns a random natural number less than k, which must be positive.
[procedure] (random-integer a b) -> integer- a
- integer
- b
- integer
Returns a random integer n such that (<= a n) and (< n b).
[procedure] (random-bits num)- num
- integer
Returns a random natural smaller than (expt 2 num); num must be positive. For powers of two, this is faster than using random-natural, which is implemented in terms of random-bits, using biased rejection sampling.
Measuring Error
[procedure] (absolute-error x r) -> number- x
- number
- r
- number
Usually computes (abs (- x r)) using exact rationals, but handles non-rational reals such as +inf.0 specially.
Examples:
> (absolute-error 1/2 1/2) 0 > (absolute-error 0.14285714285714285 1/7) 7.93016446160826e-18 > (absolute-error +inf.0 +inf.0) 0.0 > (absolute-error +inf.0 +nan.0) +inf.0 > (absolute-error 1e-20 0.0) 1e-20 > (absolute-error (- 1.0 (fp 4999999/5000000)) 1/5000000) 5.751132903242251e-18[procedure] (relative-error x r) -> number
- x
- number
- r
- number
Measures how close an approximation x is to the correct value r, relative to the magnitude of r.
This function usually computes (abs (/ (- x r) r)) using exact rationals, but handles non-rational reals such as +inf.0 specially, as well as r = 0.
> (relative-error 1/2 1/2) 0 > (relative-error 0.14285714285714285 1/7) 5.551115123125783e-17 > (relative-error +inf.0 +inf.0) 0.0 > (relative-error +inf.0 +nan.0) +inf.0 > (relative-error 1e-20 0.0) +inf.0 > (relative-error (- 1.0 (fp 4999999/5000000)) 1/5000000) 2.8755664516211255e-11
In the last two examples, relative error is high because the result is near zero. (Compare the same examples with absolute-error.) Because flonums are particularly dense near zero, this makes relative error better than absolute error for measuring the error in a flonum approximation. An even better one is error in ulps; see fpulp and fpulp-error.
(math flonum)
Flonum functions, including high-accuracy support
Note: This library uses the fp prefix rather than the original library's fl prefix for consistency with (chicken flonum).
Note: This is currently missing procedures from racket/flonum that the original racket library re-exports.
Note: Currently, this module is not very well tested.
Additional Flonum Fnuctions
[procedure] (fp x) -> flonum- x
- number
Equivalent to exact->inexact, but much easier to read and write.
Examples:
> (fp 1/2) 0.5 > (fp 0.5) 0.5 > (fp #i0.5) 0.5[procedure] (fpsgn x) -> flonum
[procedure] (fpeven? x) -> flonum
[procedure] (fpodd? x) -> flonum
- x
- flonum
Like sgn, even?, and odd?, but restricted to flonum input.
Examples:
> (map fpsgn '(-2.0 -0.0 0.0 2.0)) '(-1.0 0.0 0.0 1.0) > (map fpeven? '(2.0 1.0 0.5)) '(#t #f #f) > (map fpodd? '(2.0 1.0 0.5)) '(#f #t #f)[procedure] (fprational? x) -> boolean
[procedure] (fpinfinite? x) -> boolean
[procedure] (fpnan? x) -> boolean
[procedure] (fpinteger? x) -> boolean
- x
- flonum
Like rational?, infinite?, nan?, and integer?, but restricted to flonum input.
[procedure] (fphypot x y) -> flonum- x
- flonum
- y
- flonum
Computes (fpsqrt (+ (* x x) (* y y))) in way that overflows only when the answer is too large.
Examples:
> (fpsqrt (+ (* 1e+200 1e+200) (* 1e+199 1e+199))) +inf.0 > (fphypot 1e+200 1e+199) 1.0049875621120889e+200[procedure] (fpsum xs) -> flonum
- xs
- (list-of flonum)
Like (apply + xs), but incurs rounding error only once.
Examples:
> (+ 1.0 1e-16) 1.0 > (+ (+ 1.0 1e-16) 1e-16) 1.0 > (fpsum '(1.0 1e-16 1e-16)) 1.0000000000000002
The sum function does the same for heterogenous lists of reals.
Worst-case time complexity is O(n^2), though the pathological inputs needed to observe quadratic time are exponentially improbable and are hard to generate purposely. Expected time complexity is O(n log(n)).
See fpvector-sums for a variant that computes all the partial sums in xs.
[procedure] (fpsinh x) -> flonum[procedure] (fpcosh x) -> flonum
[procedure] (fptanh x) -> flonum
- x
- flonum
Return the hyperbolic sine, cosine, and tangent of x, respectively.
Maximum observed error is 2 ulps (see fpulp), making these functions (currently) much more accurate than their (math base) counterparts (Note: currently missing). They also return sensible values on the largest possible domain.
[procedure] (fpsinh x) -> flonum[procedure] (fpcosh x) -> flonum
[procedure] (fptanh x) -> flonum
- x
- flonum
Return the inverse hyperbolic sine, cosine, and tangent of y, respectively.
These functions are as robust and accurate as their corresponding inverses.
[procedure] (fpfactorial n) -> flonum[procedure] (fpbinomial n k) -> flonum
[procedure] (fppermutations n k) -> flonum
[procedure] (fpmultinomial n ks) -> flonum
- n
- flonum
- k
- flonum
- ks
- (list-of flonum)
Like (fp (factorial (fp->exact-integer n))) and so on, but computed in constant time. Also, these return +nan.0 instead of raising exceptions.
For factorial-like functions that return sensible values for non-integers, see log-gamma and log-beta (Note: currently missing).
[procedure] (fplog1p x) -> flonum[procedure] (fpexpm1 x) -> flonum
- x
- flonum
Like (fplog (+ 1.0 x)) and (- (fpexp x) 1.0), but accurate when x is small (within 1 ulp - see fpulp).
For example, one difficult input for (fplog (+ 1.0 x)) and (- (fpexp x) 1.0) is x = 1e-14, which fplog1p and fpexpm1 compute correctly:
> (fplog (+ 1.0 1e-14)) 9.992007221626358e-15 > (fplog1p 1e-14) 9.99999999999995e-15 > (- (fpexp 1e-14) 1.0) 9.992007221626409e-15 > (fpexpm1 1e-14) 1.0000000000000049e-14
These functions are mutual inverses:
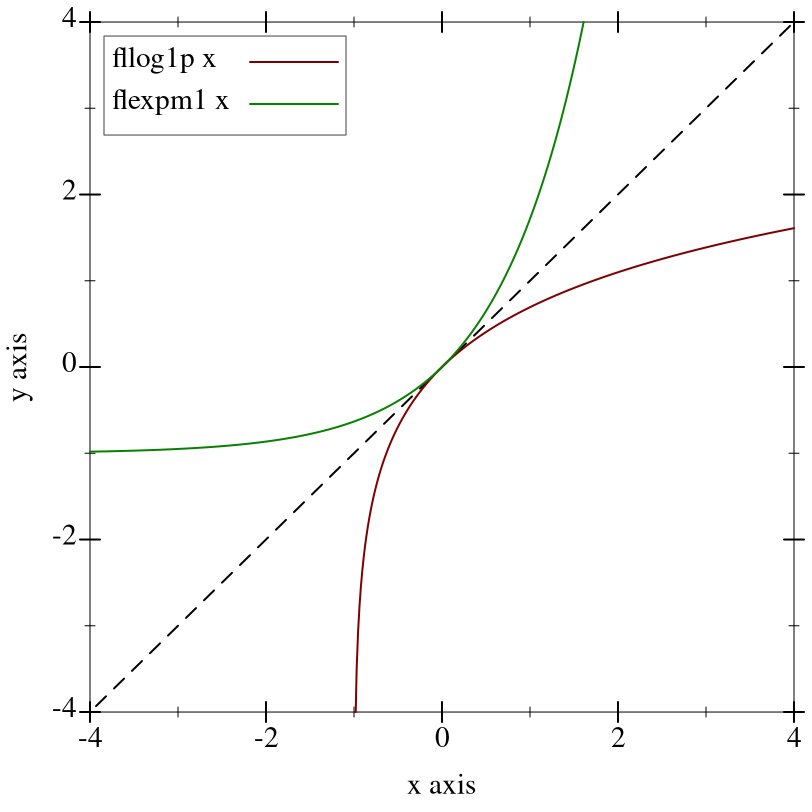
Notice that both graphs pass through the origin. Thus, inputs close to 0.0, around which flonums are particularly dense, result in outputs that are also close to 0.0. Further, both functions are approximately the identity function near 0.0, so the output density is approximately the same.
Many flonum functions defined in terms of fplog and fpexp become much more accurate when their defining expressions are put in terms of fplog1p and fpexpm1. The functions exported by this module and by math/special-functions use them extensively.
One notorious culprit is (fpexpt (- 1.0 x) y), when x is near 0.0. Computing it directly too often results in the wrong answer:
> (fpexpt (- 1.0 1e-20) 1e+20)
1.0
We should expect that multiplying a number just less than 1.0 by itself that many times would result in something less than 1.0. The problem comes from subtracting such a small number from 1.0 in the first place:
> (- 1.0 1e-20)
1.0
Fortunately, we can compute this correctly by putting the expression in terms of fplog1p, which avoids the error-prone subtraction:
> (fpexp (* 1e+20 (fplog1p (- 1e-20))))
0.36787944117144233
See fpexpt1p, which is more accurate still.
[procedure] (fpexpt1p x y) -> flonum- x
- flonum
- y
- flonum
Like (fpexpt (+ 1.0 x) y), but accurate for any x and y.
[procedure] (fpexpt+ x1 x2 y) -> flonum- x1
- flonum
- x2
- flonum
- y
- flonum
Like (fpexpt (+ x1 x2) y), but more accurate.
[procedure] (fpexp2 x) -> flonum- x
- flonum
Equivalent to fpexpt 2.0 x, but faster when x is an integer.
[procedure] (fplog2 x) -> flonum- x
- flonum
Computes the base-2 log of x more accurately than (/ (fplog x) (fplog 2.0)). In particular, (fplog2 x) is correct for any power of two x.
Examples:
> (fplog2 4.5) 2.169925001442312 > (/ (fplog (fpexp2 -1066.0)) (fplog 2.0)) -1066.0000000000002 > (fplog2 (fpexp2 -1066.0)) -1066.0
Maximum observed error is 0.5006 ulps (see fpulp), but is almost always no more than 0.5 (i.e. it is almost always correct).
[procedure] (fplogb b x) -> flonum- b
- flonum
- x
- flonum
Computes the base-b log of x more accurately than (/ (fplog x) (fplog b)), and handles limit values correctly.
Maximum observed error is 2.1 ulps (see fpulp), but is usually less than 0.7 (i.e. near rounding error).
Except possibly at limit values (such as 0.0 and +inf.0, and b = 1.0) and except when the inner expression underflows or overflows, fplogb approximately meets these identities for b > 0.0:
- Left inverse: (fplogb b (fpexpt b y)) = y
- Right inverse: (fpexpt b (fplogb b x)) = x when x > 0.0
Unlike with fpexpt, there is no standard for fplogb’s behavior at limit values. Fortunately, deriving the following rules (applied in order) is not prohibitively difficult.
| Case | Condition | Value |
|---|---|---|
| (fplogb b 1.0) | 0.0 | |
| (fplogb 1.0 x) | +nan.0 | |
| (fplogb b x) | b < 0.0 or x < 0.0 | +nan.0 |
| Double limits | ||
| (fplogb 0.0 0.0) | +inf.0 | |
| (fplogb 0.0 +inf.0) | -inf.0 | |
| (fplogb +inf 0.0) | -inf.0 | |
| (fplogb +inf +inf.0) | +inf.0 | |
| Limits with respect to b | ||
| (fplogb 0.0 x) | x < 1.0 | 0.0 |
| (fplogb 0.0 x) | x > 1.0 | -0.0 |
| (fplogb +inf.0 x) | x > 1.0 | 0.0 |
| (fplogb +inf.0 x) | x < 1.0 | -0.0 |
| Limits with respect to x | ||
| (fplogb b 0.0) | x < 1.0 | +inf.0 |
| (fplogb b 0.0) | x > 1.0 | -inf.0 |
| (fplogb b +inf.0) | x > 1.0 | +inf.0 |
| (fplogb b +inf.0) | x < 1.0 | -inf.0 |
Most of these rules are derived by taking limits of the mathematical base-b log function. Except for (fplogb 1.0 x), when doing so gives rise to ambiguities, they are resolved using fpexpt’s behavior, which follows the IEEE 754 and C99 standards for {{pow}.
For example, consider (fplogb 0.0 0.0). Taking an interated limit, we get ∞ if the outer limit is with respect to x, or 0 if the outer limit is with respect to b. This would normally mean (fplogb 0.0 0.0) = +nan.0.
However, choosing +inf.0 ensures that these additional left-inverse and right-inverse identities hold:
(fplogb 0.0 (fpexpt 0.0 +inf.0)) = +inf.0 (fpexpt 0.0 (fplogb 0.0 0.0)) = 0.0
Further, choosing 0.0 does not ensure that any additional identities hold.
[procedure] (fpbracketed-root f a b) -> flonum- f
- (flonum -> flonum)
- a
- flonum
- b
- flonum
Uses the Brent-Dekker method to find a floating-point root of f (a flonum x for which (f x) is very near a zero crossing) between a and b. The values (f a) and (f b) must have opposite signs, but a and b may be in any order.
Examples:
> (define (f x) (+ 1.0 (* (+ x 3.0) (sqr (- x 1.0))))) > (define x0 (fpbracketed-root f -4.0 2.0)) > (f (fpprev x0)) -7.105427357601002e-15 > (f x0) 6.661338147750939e-16 > (fpbracketed-root f -1.0 2.0) +nan.0
Caveats:
- There is no guarantee that fpbracketed-root will find any particular root. Moreover, future updates to its implementation could make it find different ones.
- There is currently no guarantee that it will find the closest x to an exact root.
- It currently runs for at most 5000 iterations.
It usually requires far fewer iterations, especially if the initial bounds a and b are tight.
[procedure] (make-fpexpt x) -> (flonum -> flonum)- x
- number
Equivalent to (λ (y) (fpexpt x y)) when x is a flonum, but much more accurate for large y when x cannot be exactly represented by a flonum.
Suppose we want to compute π^y, where y is a flonum. If we use flexpt with an approximation of the irrational base π, the error is low near zero, but grows with distance from the origin. Using make-fpexpt, the error is near rounding error everywhere.
[procedure] (fpsqrt1pm1 x) -> flonum- x
- flonum
Like (- (fpsqrt (+ 1.0 x)) 1.0), but accurate when x is small.
[procedure] (fplog1pmx x) -> flonum- x
- flonum
Like (- (fplog1p x) x), but accurate when x is small.
[procedure] (fpexpsqr x) -> flonum- x
- flonum
Like (fpexp (* x x)), but accurate when x is large.
[procedure] (fpgauss x) -> flonum- x
- flonum
Like (fpexp (- (* x x))), but accurate when x is large.
[procedure] (fpexp1p x) -> flonum- x
- flonum
Like (fpexp (+ 1.0 x)), but accurate when x is near a power of 2.
[procedure] (fpsinpix x) -> flonum[procedure] (fpcospix x) -> flonum
[procedure] (fptanpix x) -> flonum
- x
- flonum
Like (fpsin (* pi x)), (fpcos (* pi x)) and (fptan (* pi x)), respectively, but accurate near roots and singularities. When x = (+ n 0.5) for some integer n, (fptanpix x) = +nan.0.
[procedure] (fpcscpix x) -> flonum[procedure] (fpsecpix x) -> flonum
[procedure] (fpcotpix x) -> flonum
- x
- flonum
Like (/ 1.0 (fpsinpix x)), (/ 1.0 (fpcospix x)) and (/ 1.0 (fptanpix x)), respectively, but the first two return +nan.0 at singularities and fpcotpix avoids a double reciprocal.
Log-Space Arithmetic
It is often useful, especially when working with probabilities and probability densities, to represent nonnegative numbers in log space, or as the natural logs of their true values. Generally, the reason is that the smallest positive flonum is too large.
For example, say we want the probability density of the standard normal distribution (the bell curve) at 50 standard deviations from zero:
(Note: (math distributions) is still un-implemented in CHICKEN, but should arrive in a later release)
> (import (math distributions)) > (pdf (normal-dist) 50.0) 0.0
Mathematically, the density is nonzero everywhere, but the density at 50 is less than +min.0. However, its density in log space, or its log-density, is representable:
> (pdf (normal-dist) 50.0 #t)
-1250.9189385332047
While this example may seem contrived, it is very common, when computing the density of a vector of data, for the product of the densities to be too small to represent directly.
In log space, exponentiation becomes multiplication, multiplication becomes addition, and addition becomes tricky. See lg+ and lgsum for solutions.
[procedure] (lg* logx logy) -> flonum[procedure] (lg/ logx logy) -> flonum
[procedure] (lgprod logxs) -> flonum
- logx
- flonum
- logy
- flonum
- logxs
- (list-of flonum)
Equivalent to (fp+ logx logy), (fp- logx logy) and (fpsum logxs), respectively.
[procedure] (lg+ logx logy) -> flonum[procedure] (lg- logx logy) -> flonum
- logx
- flonum
- logy
- flonum
Like (fplog (+ (fpexp logx) (fpexp logy))) and (fplog (- (fpexp logx) (fpexp logy))), respectively, but more accurate and less prone to overflow and underflow.
When logy > logx, lg- returns +nan.0. Both functions correctly treat -inf.0 as log-space 0.0.
To add more than two log-space numbers with the same guarantees, use lgsum.
Examples:
> (lg+ (fplog 0.5) (fplog 0.2)) -0.35667494393873234 > (fpexp (lg+ (fplog 0.5) (fplog 0.2))) 0.7000000000000001 > (lg- (fplog 0.5) (fplog 0.2)) -1.203972804325936 > (fpexp (lg- (fplog 0.5) (fplog 0.2))) 0.30000000000000004 > (lg- (fplog 0.2) (fplog 0.5)) +nan.0
Though more accurate than a naive implementation, both functions are prone to catastrophic cancellation (see fpulp-error) in regions where they output a value close to 0.0 (or log-space 1.0). While these outputs have high relative error, their absolute error is very low, and when exponentiated, nearly have just rounding error. Further, catastrophic cancellation is unavoidable when logx and logy themselves have error, which is by far the common case.
These are, of course, excuses—but for floating-point research generally. There are currently no reasonably fast algorithms for computing lg+ and lg- with low relative error. For now, if you need that kind of accuracy, use (math bigfloat) (Note: still unimplemented in CHICKEN).
[procedure] (lgsum logxs) -> flonum- logxs
- flonum
Like folding lg+ over logxs, but more accurate. Analogous to fpsum.
[procedure] (lg1+ logx) -> flonum[procedure] (lg1- logx) -> flonum
- logx
- flonum
Equivalent to (lg+ (fplog 1.0) logx) and (lg- (fplog 1.0) logx), respectively, but faster.
[procedure] (fpprobability? x [log?])- x
- flonum
- log?
- boolean
When log? is #f, returns #t when (<= 0.0 x 1.0). When log? is #t, returns #t when (<= -inf.0 x 0.0)
Examples:
> (fpprobability? -0.1) #f > (fpprobability? 0.5) #t > (fpprobability? +nan.0 #t) #f
Debugging Flonum Functions
The following functions and constants are useful in authoring and debugging flonum functions that must be accurate on the largest possible domain.
Measuring Floating-Point Error
[procedure] (fpulp x) -> flonum- x
- flonum
Returns x's ulp or unit in last place: the magnitude of the least significant bit in x.
Examples:
> (fpulp 1.0) 2.220446049250313e-16 > (fpulp 1e-100) 1.2689709186578246e-116 > (fpulp 1e+200) 1.6996415770136547e+184[procedure] (fpulp-error x r) -> flonum
- x
- flonum
- r
- number
Returns the absolute number of ulps difference between x and r.
For non-rational arguments such as +nan.0, fpulp-error returns 0.0 if (eqv? x r); otherwise it returns +inf.0.
A flonum function with maximum error 0.5 ulps exhibits only rounding error; it is correct. A flonum function with maximum error no greater than a few ulps is accurate. Most moderately complicated flonum functions, when implemented directly, seem to have over a hundred thousand ulps maximum error.
Examples:
> (fpulp-error 0.5 1/2) 0.0 > (fpulp-error 0.14285714285714285 1/7) 0.2857142857142857 > (fpulp-error +inf.0 +inf.0) 0.0 > (fpulp-error +inf.0 +nan.0) +inf.0 > (fpulp-error 1e-20 0.0) +inf.0 > (fpulp-error (- 1.0 (fl 4999999/5000000)) 1/5000000) 217271.6580864
he last example subtracts two nearby flonums, the second of which had already been rounded, resulting in horrendous error. This is an example of ''catastrophic cancellation'. Avoid subtracting nearby flonums whenever possible. [1]
See relative-error for a similar way to measure approximation error when the approximation is not necessarily represented by a flonum.
[1] You can make an exception if the result is to be exponentiated. If x has small absolute-error, then (exp x) has small relative-error and small fpulp-error
Flonum Constants
[constant] -max.0[constant] -min.0
[constant] +min.0
[constant] +max.0
The nonzero, rational flonums with maximum and minimum magnitude.
Example:
> (list -max.0 -min.0 +min.0 +max.0) (-1.7976931348623157e+308 -5e-324 5e-324 1.7976931348623157e+308)[constant] epsilon.0
The smallest flonum that can be added to 1.0 to yield a larger number, or the magnitude of the least significant bit in 1.0.
Examples:
> epsilon.0
2.220446049250313e-16
> (fpulp 1.0)
2.220446049250313e-16
Epsilon is often used in stopping conditions for iterative or additive approximation methods. For example, the following function uses it to stop Newton’s method to compute square roots. (Please do not assume this example is robust.)
(define (newton-sqrt x)
(let loop ([y (* 0.5 x)])
(define dy (/ (- x (sqr y)) (* 2.0 y)))
(if (<= (abs dy) (abs (* 0.5 epsilon.0 y)))
(+ y dy)
(loop (+ y dy)))))
When (<= (abs dy) (abs (* 0.5 epsilon.0 y))), adding dy to y rarely results in a different flonum. The value 0.5 can be changed to allow looser approximations. This is a good idea when the approximation does not have to be as close as possible (e.g. it is only a starting point for another approximation method), or when the computation of dy is known to be inaccurate.
Approximation error is often understood in terms of relative error in epsilons. Number of epsilons relative error roughly corresponds with error in ulps, except when the approximation is subnormal.
Low-Level Flonum Operations
[procedure] (flonum->bit-field x) -> integer- x
- flonum
Returns the bits comprising x as an integer. A convenient shortcut for composing integer-bytes->integer with real->floating-point-bytes (Note: neither of these is in CHICKEN).
Examples:
> (number->string (flonum->bit-field -inf.0) 16) "fff0000000000000" > (number->string (flonum->bit-field +inf.0) 16) "7ff0000000000000" > (number->string (flonum->bit-field -0.0) 16) "8000000000000000" > (number->string (flonum->bit-field 0.0) 16) "0" > (number->string (flonum->bit-field -1.0) 16) "bff0000000000000" > (number->string (flonum->bit-field 1.0) 16) "3ff0000000000000" > (number->string (flonum->bit-field +nan.0) 16) "7ff8000000000000"[procedure] (bit-field->flonum i) -> flonum
- i
- integer
The inverse of flonum->bit-field.
[procedure] (flonum->ordinal x) -> integer- x
- flonum
Returns the signed ordinal index of x in a total order over flonums.
When inputs are not +nan.0, this function is monotone and symmetric; i.e. if (fp<= x y) then (<= (flonum->ordinal x) (flonum->ordinal y)), and (= (flonum->ordinal (- x)) (- (flonum->ordinal x))).
Examples:
> (flonum->ordinal -inf.0) -9218868437227405312 > (flonum->ordinal +inf.0) 9218868437227405312 > (flonum->ordinal -0.0) 0 > (flonum->ordinal 0.0) 0 > (flonum->ordinal -1.0) -4607182418800017408 > (flonum->ordinal 1.0) 4607182418800017408 > (flonum->ordinal +nan.0) 9221120237041090560
These properties mean that flonum->ordinal does not distinguish -0.0 and 0.0.
[procedure] (ordinal->flonum i) -> flonum- i : integer
The inverse of flonum->ordinal.
[procedure] (flonums-between x y) -> integer- x
- flonum
- y
- flonum
Returns the number of flonums between x and y, excluding one endpoint. Equivalent to (- (flonum->ordinal y) (flonum->ordinal x)).
Examples:
> (flonums-between 0.0 1.0) 4607182418800017408 > (flonums-between 1.0 2.0) 4503599627370496 > (flonums-between 2.0 3.0) 2251799813685248 > (flonums-between 1.0 +inf.0) 4611686018427387904[procedure] (fpstep x n) -> flonum
- x
- flonum
- n
- integer
Returns the flonum n flonums away from x, according to flonum->ordinal. If x is +nan.0, returns +nan.0.
Examples:
> (fpstep 0.0 1) 5e-324 > (fpstep (fpstep 0.0 1) -1) 0.0 > (fpstep 0.0 -1) -5e-324 > (fpstep +inf.0 1) +inf.0 > (fpstep +inf.0 -1) 1.7976931348623157e+308 > (fpstep -inf.0 -1) -inf.0 > (fpstep -inf.0 1) -1.7976931348623157e+308 > (fpstep +nan.0 1000) +nan.0[procedure] (fpnext x) -> flonum
[procedure] (fpprev x) -> flonum
- x
- flonum
Equivalent to (flstep x 1) and (flstep x -1), respectively.
[procedure] (fpsubnormal? x) -> boolean- x
- flonum
Returns #t when x is a subnormal number.
Though flonum operations on subnormal numbers are still often implemented by software exception handling, the situation is improving. Robust flonum functions should handle subnormal inputs correctly, and reduce error in outputs as close to zero ulps as possible (see fpulp).
[constant] -max-subnormal.0[constant] +max-subnormal.0
The maximum positive and negative subnormal flonums. A flonum x is subnormal when it is not zero and (<= (abs x) +max-subnormal.0).
Example:
> +max-subnormal.0 2.225073858507201e-308
Double-Double Operations
For extra precision, floating-point computations may use two nonoverlapping flonums to represent a single number. Such pairs are often called double-double numbers. The exact sum of the pair is the number it represents. (Because they are nonoverlapping, the floating-point sum is equal to the largest.)
For speed, especially with arithmetic operations, there is no data type for double-double numbers. They are always unboxed: given as two arguments, and received as two values. In both cases, the number with higher magnitude is first.
Inputs are never checked to ensure they are sorted and nonoverlapping, but outputs are guaranteed to be sorted and nonoverlapping if inputs are.
[procedure] (fp2 x [y]) -> flonum flonum- x
- number (or flonum if y passed)
- y
- flonum
Converts a real number or the sum of two flonums into a double-double.
> (fp 1/7) 0.14285714285714285 > (relative-error (fp 1/7) 1/7) 5.551115123125783e-17 > (define-values (x2 x1) (fp2 1/7)) > (list x2 x1) (0.14285714285714285 7.93016446160826e-18) > (fp (relative-error (+ (inexact->exact x2) (inexact->exact x1)) 1/7)) 3.0814879110195774e-33
Notice that the exact sum of x2 and x1 in the preceeding example has very low relative error.
If x is not rational, fp2 returns (values x 0.0).
[procedure] (fp2->real x2 x1) -> number- x2
- flonum
- x1
- flonum
Returns the exact sum of x2 and x1 if x2 is rational, x2 otherwise.
> (define-values (x2 x1) (fp2 1/7)) > (fp2->real x2 x1) 46359793379775246683308002939465/324518553658426726783156020576256[procedure] (fp2? x2 x1) -> boolean
When x2 is rational, returns #t when (fpabs x2) > (fpabs x1) and x2 and x1 are nonoverlapping. When x2 is not rational, returns (fp= x1 0.0).
Examples:
> (define-values (x2 x1) (fl2 1/7)) > (fl2? x2 x1) #t > (fl2? 0.14285714285714285 0.07692307692307693) #f > (fl2? +inf.0 0.0001) #f
This function is quite slow, so it is used only for testing.
[procedure] (fp+/error x y) -> flonum flonum[procedure] (fp-/error x y) -> flonum flonum
[procedure] (fp*/error x y) -> flonum flonum
[procedure] (fp//error x y) -> flonum flonum
[procedure] (fpsqr/error x) -> flonum flonum
[procedure] (fpsqrt/error x) -> flonum flonum
[procedure] (fpexp/error x) -> flonum flonum
[procedure] (fpexpm1/error x) -> flonum flonum
Compute the same values as (fp+ x y), (fp- x y), (fp* x y), (fp/ x y), (fp* x x), (fpsqrt x), (fpexp x) and (fpexpm1 x), but return the normally rounded-off low-order bits as the second value. The result is an unboxed double-double.
Use these functions to generate double-double numbers directly from the results of floating-point operations.
For fpexp/error and fpexpm1/error, the largest observed error is 3 ulps. (See fp2ulp.) For the rest, the largest observed error is 0.5 ulps.
[procedure] (fp2zero? x2 x1) -> boolean[procedure] (fp2rational? x2 x1) -> boolean
[procedure] (fp2positive? x2 x1) -> boolean
[procedure] (fp2negative? x2 x1) -> boolean
[procedure] (fp2infinite? x2 x1) -> boolean
[procedure] (fp2nan? x2 x1) -> boolean
- x2
- flonum
- x1
- flonum
Like zero?, rational?, positive?, negative?, infinite? and nan?, but for double-double flonums.
[procedure] (fp2+ x2 x1 y2 [y1]) -> flonum flonum[procedure] (fp2- x2 x1 y2 [y1]) -> flonum flonum
[procedure] (fp2* x2 x1 y2 [y1]) -> flonum flonum
[procedure] (fp2/ x2 x1 y2 [y1]) -> flonum flonum
[procedure] (fp2abs x2 [x1]) -> flonum flonum
[procedure] (fp2sqr x2 [x1]) -> flonum flonum
[procedure] (fp2sqrt x2 [x1]) -> flonum flonum
- x2
- flonum
- x1
- flonum
- y2
- flonum
- y1
- flonum
Arithmetic and square root for double-double flonums. For arithmetic, error is less than 8 ulps. (See fp2ulp.) For fp2sqr and fp2sqrt, error is less than 1 ulp, and fp2abs is exact.
[procedure] (fp2= x2 x1 y2 y1)[procedure] (fp2> x2 x1 y2 y1)
[procedure] (fp2< x2 x1 y2 y1)
[procedure] (fp2>= x2 x1 y2 y1)
[procedure] (fp2<= x2 x1 y2 y1)
- x2
- flonum
- x1
- flonum
- y2
- flonum
- y1
- flonum
Comparison functions for double-double flonums.
[procedure] (fp2exp x2 x1)[procedure] (fp2log x2 x1)
[procedure] (fp2expm1 x2 x1)
[procedure] (fp2log1p x2 x1)
Like fpexp, fplog, fpexpm1 and fplog1p, but for double-double flonums.
For fp2exp and fp2expm1, error is less than 3 ulps. (See flpulp.) For fp2log and {{}fp2log1p}}, error is less than 2 ulps.
Debugging Double-Double Functions
[procedure] (fp2ulp x2 x1) -> flonum[procedure] (fp2ulp-error x2 x1 r) -> flonum
- x2
- flonum
- x1
- flonum
- r
- flonum
Like fpulp and fpulp-error, but for double-double flonums.
The unit in last place of a double-double is that of the higher-order of the pair, shifted 52 bits right.
Examples:
> (fp2ulp 1.0 0.0) 4.930380657631324e-32 > (let-values ([(x2 x1) (fl2 1/7)]) (fp2ulp-error x2 x1 1/7)) 0.07142857142857142[constant] +max.hi
[constant] +max.lo
[constant] -max.hi
[constant] -max.lo
The maximum-magnitude, unboxed double-double flonums.
[constant] +max-subnormal.hi[constant] -max-subnormal.hi
The high-order flonum of the maximum-magnitude, subnormal double-double flonums.
> +max-subnormal.0 2.225073858507201e-308 > +max-subnormal.hi 1.0020841800044864e-292
Try to avoid computing with double-doubles in the subnormal range in intermediate computations.
Low-level Double-Double Operations
The following syntactic forms are fast versions of functions like fp+/error. They are fast because they make assumptions about the magnitudes of and relationships between their arguments, and do not handle non-rational double-double flonums properly.
[syntax] (fast-mono-fp+/error x y)[syntax] (fast-mono-fp-/error x y)
Return two values: (fp+ x y) or (fp- x y), and its rounding error. Both assume (fpabs x) > (fpabs y). The values are unspecified when x or y is not rational.
[syntax] (fast-fp+/error x y)[syntax] (fast-fp-/error x y)
Like fast-mono-fp+/error and fast-mono-fp-/error, but do not assume (fpabs x) > (fpabs y).
[syntax] (fast-fl*/error x y)[syntax] (fast-fl//error x y)
[syntax] (fast-flsqr/error x)
Like fp*/error, fp//error and fpsqr/error, but faster, and may return garbage when an argument is subnormal or nearly infinite.
[syntax] (fpsplit x)Returns nonoverlapping (values y2 y1), each with 26 bits precision, with (fpabs y2) > (fpabs y1), such that (fp+ y2 y1) = x. For (flabs x) > 1.3393857490036326e+300, returns (values +nan.0 +nan.0).
Used to implement double-double multiplication.
Additional Flonum Vector Functions
[procedure] (build-fpvector n proc) -> f64vector- n
- integer
- proc
- (fixnum -> flonum)
Creates a length-n flonum vector by applying proc to the indexes from 0 to (- n 1). Analogous to build-vector.
Example:
> (build-fpvector 10 fl) #f64(0.0 1.0 2.0 3.0 4.0 5.0 6.0 7.0 8.0 9.0)[syntax] (inline-build-fpvector n proc)
- n
- integer
- proc
- (fixnum -> flonum)
Like build-flvector, but always inlined. This increases speed at the expense of code size.
[syntax] (fpvector-map proc xs xss ...) -> f64vector- proc
- (flonum flonum ... -> flonum)
- xs
- f64vector
- xss
- f64vector
Applies proc to the corresponding elements of xs and xss. Analogous to vector-map.
The proc is meant to accept the same number of arguments as the number of its following flonum vector arguments.
[syntax] (inline-fpvector-map proc xs xss ...)- proc
- (flonum flonum ... -> flonum)
- xs
- f64vector
- xss
- f64vector
Like flvector-map, but always inlined.
[procedure] (fpvector-copy! dest dest-start src [src-start src-end]) -> void- dest
- f64vector
- dest-start
- integer
- src
- f64vector
- src-start
- integer
- src-end
- integer
Like vector-copy! but for flonum vectors.
[procedure] (list->fpvector vs) -> f64vector[procedure] (fpvector->list xs) -> (list-of flonum)
[procedure] (vector->fpvector vs) -> f64vector
[procedure] (fpvector->vector xs) -> (vector-of flonum)
- vs
- (list-of number)
- xs
- f64vector
Convert between lists and flonum vectors, and between vectors and flonum vectors.
[procedure] (fpvector+ xs ys) -> f64vector[procedure] (fpvector* xs ys) -> f64vector
[procedure] (fpvector- xs [ys]) -> f64vector
[procedure] (fpvector/ xs [ys]) -> f64vector
[procedure] (fpvector-scale xs y) -> f64vector
[procedure] (fpvector-abs xs) -> f64vector
[procedure] (fpvector-sqr xs) -> f64vector
[procedure] (fpvector-sqrt xs) -> f64vector
[procedure] (fpvector-min xs) -> f64vector
[procedure] (fpvector-max xs) -> f64vector
- xs
- f64vector
- ys
- f64vector
- y
- flonum
Arithmetic lifted to operate on flonum vectors.
[procedure] (fpvector-sum xs) -> flonum- xs
- f64vector
Like fpsum, but operates on flonum vectors. In fact, fpsum is defined in terms of fpvector-sum.
[procedure] (fpvector-sums xs) -> f64vector- xs
- f64vector
Computes the partial sums of the elements in xs in a way that incurs rounding error only once for each partial sum.
Example:
> (fpvector-sums #f64(1.0 1e-16 1e-16 1e-16 1e-16 1e+100 -1e+100)) #f64(1.0 1.0 1.0 1.0 1.0 1e+100 1.0)
Compare the same example computed by direct summation:
> (import srfi-1) > (cdr (reverse (fold (lambda (x xs) (cons (+ x (first xs)) xs)) (list 0.0) '(1.0 1e-16 1e-16 1e-16 1e-16 1e+100 -1e+100)))) '(1.0 1.0 1.0 1.0 1.0 1e+100 0.0)
(math number-theory)
Number-theoretic functions
Congruences and modular arithmetic
[procedure] (divides? m n) -> boolean- m
- integer
- n
- integer
Returns #t if m divides n, #f otherwise.
Examples:
> (divides? 2 9) #f > (divides? 2 8) #t
Note that 0 cannot divide anything:
> (divides? 0 5) #f > (divides? 0 0) #f
Practically, if (divides? m n) is #t, then (/ n m) will return an integer.
Wikipedia: Divisor
[procedure] (bezout a b c ...) -> (list-of integer)- a
- integer
- b
- integer
- c
- integer
Given integers a b c ... returns a list of integers (list u v w ...) such that (gcd a b c ...) = (+ (* a u) (* b v) (* c w) ...).
Examples:
> (bezout 6 15) (-2 1) > (+ (* -2 6) (* 1 15)) 3 > (gcd 6 15) 3
Wikipedia: Bézout's Identity
[procedure] (coprime? a b ...) -> boolean- a
- integer
- b
- integer
Returns #t if the integers a b ... are coprime. Formally, a set of integers is considered coprime (also called relatively prime) if their greatest common divisor is 1.
Example:
> (coprime? 2 6 15)
#t
Wikipedia: Coprime
[procedure] (pairwise-coprime? a b ...) -> boolean- a
- integer
- b
- integer
Returns #t if the integers a b ... are pairwise coprime, meaning that each pair of integers is coprime.
The numbers 2, 6 and 15 are coprime, but not pairwise coprime, because 6 and 15 share the factor 3:
> (pairwise-coprime? 2 6 15)
#f
Wikipedia:Pairwise Coprime
[procedure] (solve-chinese as ns) -> integer- as
- (list-of integer)
- ns
- (list-of integer)
Given a length-k list of integers as and a length-k list of coprime moduli ns, (solve-chinese as ns) returns the least natural number x that is a solution to the equations
x = a₁ (mod n₁) ... x = aₖ (mod nₖ)
The solution x is less than (* n1 ... nk).
The moduli ns must all be positive.
What is the least number x that when divided by 3 leaves a remainder of 2, when divided by 5 leaves a remainder of 3, and when divided by 7 leaves a remainder of 2?
> (solve-chinese '(2 3 2) '(3 5 7))
23
Wikipedia: Chinese Remainder Theorem
[procedure] (quadratic-residue? a n) -> boolean- a
- integer
- n
- integer
Returns #t if a is a quadratic residue modulo n, otherwise #f. The modulus n must be positive, and a must be nonnegative.
Formally, a is a quadratic residue modulo n if there exists a number x such that (* x x) = a (mod n). In other words, (quadratic-residue? a n) is #t when a is a perfect square modulo n.
Examples:
> (quadratic-residue? 0 4) #f > (quadratic-residue? 1 4) #t > (quadratic-residue? 2 4) #f > (quadratic-residue? 3 4) #f
Wikipedia: Quadratic Residue
[procedure] (quadratic-character a p) -> integer- a
- integer
- b
- integer
Returns the value of the quadratic character modulo the prime p. That is, for a non-zero a the number 1 is returned when a is a quadratic residue, and -1 is returned when a is a non-residue. If a is zero, then 0 is returned.
If a is negative or p is not positive, quadratic-character raises an error. If p is not prime, (quadratic-character a p) is indeterminate.
This function is also known as the Legendre symbol.
> (quadratic-character 0 5) 0 > (quadratic-character 1 5) 1 > (quadratic-character 2 5) -1 > (quadratic-character 3 5) -1
Wikipedia: Legendre Symbol
[procedure] (jacobi-symbol a n) -> integer- a
- integer
- n
- integer
Computes the Jacobi symbol for any nonnegative integer a and any positive odd integer n.
If n is not an odd positive integer, (jacobi-symbol a n) throws an exception.
> (jacobi-symbol 1 1) 1 > (jacobi-symbol 8 11) -1 > (jacobi-symbol 39 27) 0 > (jacobi-symbol 22 59) 1 > (jacobi-symbol 32 8) Error: (jacobi-symbol) bad argument type - not an odd integer: 8
Wikipedia: Jacobi Symbol
[procedure] (modular-inverse a n) -> integer- a
- integer
- b
- integer
Returns the inverse of a modulo n if a and n are coprime, otherwise raises an error. The modulus n must be positive, and a must be nonzero.
Formally, if a and n are coprime, b = (modular-inverse a n) is the unique natural number less than n such that (* a b) = 1 (mod n).
> (modular-inverse 2 5) 3 > (modulo (* 2 3) 5) 1
Wikipedia: Multiplicative Inverse
[procedure] (modular-expt a b n) -> integer- a
- integer
- b
- integer
- n
- integer
Computes (modulo (expt a b) n), but much more efficiently. The modulus n must be positive, and the exponent b must be nonnegative.
> (modulo (expt -6 523) 19) 13 > (modular-expt -6 523 19) 13 > (modular-expt 9 158235208 19) 4 > ; don't try this at home! (modulo (expt 9 158235208) 19) 4
Parameterized Modular Arithmetic
The math.number-theory library supports modular arithmetic parameterized on a current modulus. For example, the code
(with-modulus n
(mod= (modexpt a b) c))
corresponds with the mathematical statement a^b = c (mod n).
The current modulus is stored in a parameter that, for performance reasons, can only be set using with-modulus. (The basic modular operators cache parameter reads, and this restriction guarantees that the cached values are current. NOTE: I'm not entirely sure this is true for the CHICKEN port, as a slightly more complicated racket syntax-case has been turned into a simple syntax-rule for (parameterize ...))
Wikipedia: Modular Arithmetic
[syntax] (with-modulus n body ...)- n
- integer
Alters the current modulus within the dynamic extent of body. The expression n must evaluate to a positive integer.
By default, the current modulus is 1, meaning that every modular arithmetic expression that does not raise an error returns 0.
[procedure] (current-modulus) -> integerReturns the current modulus.
Examples:
> (current-modulus) 1 > (with-modulus 5 (current-modulus)) 5[procedure] (mod x) -> integer
- x
- exact rational
Converts a rational number x to a natural number less than the current modulus.
If x is an integer, this is equivalent to (modulo x n). If x is a fraction, an integer input is generated by multiplying its numerator by its denominator’s modular inverse.
Examples:
> (with-modulus 7 (mod (* 218 7))) 0 > (with-modulus 7 (mod 3/2)) 5 > (with-modulus 7 (mod/ 3 2)) 5 > (with-modulus 7 (mod 3/7)) Error: (modular-inverse) bad argument type - not coprime to modulus 7: 7[procedure] (mod+ a ...) -> integer
[procedure] (mod* a ...) -> integer
- a
- integer
Equivalent to (modulo (+ a ...) (current-modulus)) and (modulo (* a ...) (current-modulus)), respectively, but generate smaller intermediate values.
[procedure] (modsqr a) -> integer[procedure] (modexpt a b) -> integer
- a
- integer
- b
- integer
Equivalent to (mod* a a) and (modular-expt a b (current-modulus)), respectively.
[procedure] (mod- a b ...) -> integer- a
- integer
- b
- integer
Equivalent to (modulo (- a b ...) (current-modulus)), but generates smaller intermediate values. Note that (mod- a) = (mod (- a)).
[procedure] (mod/ a b ...) -> integer- a
- integer
- b
- integer
Divides a by (* b ...), by multiplying a by the multiplicative inverse of (* b ...). The one-argument variant returns the modular inverse of a.
Note that (mod/ a b ...) is not equivalent to (modulo (/ a b ...) (current-modulus)); see mod= for a demonstration.
[procedure] (mod= a b ...) -> boolean[procedure] (mod< a b ...) -> boolean
[procedure] (mod<= a b ...) -> boolean
[procedure] (mod> a b ...) -> boolean
[procedure] (mod>= a b ...) -> boolean
- a
- integer
- b
- integer
Each of these is equivalent to (op (mod a) (mod b) ...), where op is the corresponding numeric comparison function. Additionally, when given one argument, the inequality tests always return #t.
Suppose we wanted to know why 17/4 = 8 (mod 15), but 51/12 (mod 15) is undefined, even though normally 51/12 = 17/4. In code,
> (with-modulus 15 (mod/ 17 4)) 8 > (/ 51 12) 17/4 > (with-modulus 15 (mod/ 51 12)) Error: (modular-inverse) bad argument type - not coprime to modulus 15: 12
We could try to divide by brute force: find, modulo 15, all the numbers a for which (mod* a 4) is 17, then find all the numbers b for which (mod* a 12) is 51.
(import srfi-42) > (with-modulus 15 (list-ec (:range a 15) (if (mod= (mod* a 4) 17)) a)) (8) > (with-modulus 15 (list-ec (:range a 15) (if (mod= (mod* a 12) 51)) a)) (3 8 13)
So the problem isn't that b doesn't exist, it's that b isn't unique.
Primes
[procedure] (prime? z) -> boolean- z
- integer
Returns #t if z is a prime, #f otherwise.
Formally, an integer z is prime when the only positive divisors of z are 1 and (abs z).
The positive primes below 20 are:
> (filter prime? (iota 20 1)) (2 3 5 7 11 13 17 19)
The corresponding negative primes are:
> (filter prime? (iota 20 0 -1)) (-2 -3 -5 -7 -11 -13 -17 -19)
Wikipedia: Prime Number
[procedure] (odd-prime? z) -> boolean- z
- integer
Returns #t if z is a odd prime, #f otherwise.
> (odd-prime? 2) #f > (odd-prime? 3) #t[procedure] (nth-prime n) -> integer
- n
- integer
Returns the nth positive prime; n must be nonnegative.
> (nth-prime 0) 2 > (nth-prime 1) 3 > (nth-prime 2) 5[procedure] (random-prime n) -> integer
- n
- integer
Returns a random prime smaller than n, which must be greater than 2.
The function random-prime picks random numbers below n until a prime is found.
> (random-prime 10) 3 > (random-prime 10) 2 > (random-prime 10) 5[procedure] (next-prime z) -> integer
- z
- integer
Returns the first prime larger than z.
> (next-prime 4) 5 > (next-prime 5) 7[procedure] (prev-prime z) -> integer
Returns the first prime smaller than z.
> (prev-prime 4) 3 > (prev-prime 5) 3[procedure] (next-primes z n) -> (list-of integer)
- z
- integer
- n
- integer
Returns list of the next n primes larger than z; n must be nonnegative.
> (next-primes 2 4) (3 5 7 11)[procedure] (prev-primes z n) -> (list-of integer)
- z
- integer
- n
- integer
Returns list of the next n primes smaller than z; n must be nonnegative.
> (prev-primes 13 4) (11 7 5 3)[procedure] (factorize n) -> (list-of (list integer integer))
- n
- integer
Returns the factorization of a natural number n. The factorization consists of a list of corresponding primes and exponents. The primes will be in ascending order.
The prime factorization of 600 = 2^3 * 3^1 * 5^2:
> (factorize 600) ((2 3) (3 1) (5 2))[procedure] (defactorize f) -> integer
- f
- (list-of (list integer integer))
Returns the natural number, whose factorization is given by f. The factorization f is represented as described in factorize.
> (defactorize '((2 3) (3 1) (5 2)))
600
Wikipedia: Integer Factorization
[procedure] (divisors z) -> (list-of integer)- z
- integer
Returns a list of all positive divisors of the integer z. The divisors appear in ascending order.
> (divisors 120) (1 2 3 4 5 6 8 10 12 15 20 24 30 40 60 120) > (divisors -120) (1 2 3 4 5 6 8 10 12 15 20 24 30 40 60 120)[procedure] (prime-divisors z) -> (list-of integer)
- z
- integer
Returns a list of all positive prime divisors of the integer z. The divisors appear in ascending order.
> (prime-divisors 120) '(2 3 5)[procedure] (prime-exponents z) -> (list-of integer)
- z
- integer
Returns a list of the exponents of in a factorization of the integer z.
> (define z (* 2 2 2 3 5 5)) > (prime-divisors z) (2 3 5) > (prime-exponents z) (3 1 2)
Roots
[procedure] (integer-root n m) -> integer- n
- integer
- m
- integer
Returns the mth integer root of n. This is the largest integer r such that (expt r m) <= n.
> (integer-root (expt 3 4) 4) 3 > (integer-root (+ (expt 3 4) 1) 4) 3[procedure] (integer-root/remainder n m) -> integer integer
- n
- integer
- m
- integer
Returns two values. The first, r, is the mth integer root of n. The second is n-r^m.
> (integer-root/remainder (expt 3 4) 4) 3 0 > (integer-root/remainder (+ (expt 3 4) 1) 4) 3 1
Powers
[procedure] (max-dividing-power a b) -> integer- a
- integer
- b
- integre
Returns the largest exponent, n, of a power with base a that divides b.
That is, (expt a n) divides b but (expt a (+ n 1)) does not divide b.
> (max-dividing-power 3 (expt 3 4)) 4 > (max-dividing-power 3 5) 0[procedure] (perfect-power m) -> (or (list integer integer) #f)
- m
- integer
If m is a perfect power, a list with two elements b and n such that (expt b n) = m is returned, otherwise #f is returned.
> (perfect-power (expt 3 4)) (3 4) > (perfect-power (+ (expt 3 4) 1)) #f[procedure] (perfect-power? m) -> boolean
- m
- integer
Returns #t if m is a perfect power, otherwise #f.
> (perfect-power? (expt 3 4)) #t > (perfect-power? (+ (expt 3 4) 1)) #f
Wikipedia: Perfect Power
[procedure] (prime-power m) -> (or (list integer integer) #f)- m
- integer
If M is a power of the form (expt p n) where p is prime, then a list with the prime and the exponent is returned, otherwise #f is returned.
> (prime-power (expt 3 4)) (3 4) > (prime-power (expt 6 4)) #f[procedure] (prime-power? m) -> boolean
- m
- integer
Returns #t if m is a prime power, otherwise #f.
> (prime-power? (expt 3 4)) #t > (prime-power? (expt 6 4)) #f > (prime-power? 1) #f > (prime-power? 0) #f[procedure] (odd-prime-power? m) -> boolean
- m
- integer
Returns #t if m is a power of an odd prime, otherwise #f.
> (odd-prime-power? (expt 2 4)) #f > (odd-prime-power? (expt 3 4)) #t > (odd-prime-power? (expt 15 4)) #f[procedure] (as-power m) -> integer integer
- m
- integer
Returns two values b and n such that m = (expt b n) and n is maximal.
> (as-power (* (expt 2 4) (expt 3 4))) 6 4 > (expt 6 4) 1296 > (* (expt 2 4) (expt 3 4)) 1296 > (as-power (* (expt 2 4) (expt 3 5))) 3888 1[procedure] (prefect-square m) -> (or integer #f)
Returns (sqrt m) if m is perfect square, otherwise #f.
> (perfect-square 9) 3 > (perfect-square 10) #f
Multiplicative and Arithmetic Functions
The functions in this section are multiplicative (with exception of the Von Mangoldt function). In number theory, a multiplicative function is a function f such that (f (* a b)) = (* (f a) (f b)) for all coprime natural numbers a and b.
[procedure] (totient n) -> integer- n
- integer
Returns the number of integers from 1 to n that are coprime with n.
This function is known as Euler's totient or phi function.
> (totient 9) 6 > (length (filter (curry coprime? 9) (range 10))) 6
Wikipedia: Euler's Totient
[procedure] (moebius-mu n) -> integer- n
- integer
Returns:
- 1 if n is a square-free product of an even number of primes
- -1 if n is a square-free product of an odd number of primes
- 0 if n has a multiple prime factor
> (moebius-mu (* 2 3 5)) -1 > (moebius-mu (* 2 3 5 7)) 1 > (moebius-mu (* 2 2 3 5 7)) 0
Wikipedia: Moebius Function
[procedure] (divisor-sum n k) -> integer- n
- integer
- k
- integer
Returns sum of the kth powers of all divisors of n.
> (divisor-sum 12 2) 210 > (apply + (map sqr (divisors 12))) 210
Wikipedia: Divisor Function
[procedure] (prime-omega n) -> integer- n
- integer
Counting multiplicities the number of prime factors of n is returned.
> (prime-omega (* 2 2 2 3 3 5))
6
[procedure] (mangoldt-lambda n) -> number
- n
- integer
The von Mangoldt function. If n=p^k for a prime p and an integer k>=1 then (log n) is returned. Otherwise 0 is returned.
Note: The Von Mangoldt function is not multiplicative.
> (mangoldt-lambda (* 3 3)) 1.0986122886681098 > (log 3) 1.0986122886681098
Wikipedia: Von Mangoldt Function
Number Sequences
[procedure] (bernoulli-number n) -> ratnum- n
- integer
Returns the nth Bernoulli number; n must be nonnegative.
> (map bernoulli-number (iota 9)) (1 -1/2 1/6 0 -1/30 0 1/42 0 -1/30)
Note that these are the first Bernoulli numbers, since (bernoulli-number 1) = -1/2.
Wikipedia: Bernoulli Number
[procedure] (eulerian-number n k) -> integer- n
- integer
- k
- integer
Returns the Eulerian number <n,k>; both arguments must be nonnegative.
> (eulerian-number 5 2)
66
Wikipedia: Eulerian Number
[procedure] (fibonacci n) -> integer- n
- integer
Returns the nth Fibonacci number; n must be nonnegative.
The ten first Fibonacci numbers:
> (map fibonacci (iota 10)) '(0 1 1 2 3 5 8 13 21 34)
Wikipedia: Fibonacci Number
[procedure] (make-fibonaci a b) -> (integer -> integer)- a
- integer
- b
- integer
Returns a function representing a Fibonacci sequence with the first two numbers a and b. The fibonacci function is defined as (make-fibonacci 0 1).
The Lucas numbers are defined as a Fibonacci sequence starting with 2 and 1:
> (map (make-fibonacci 2 1) (iota 10)) (2 1 3 4 7 11 18 29 47 76)
Wikipedia: Lucas Number
[procedure] (modular-fibonacci n m) -> integer- n
- integer
- m
- integer
Returns the nth Fibonacci number modulo m; n must be nonnegative and m must be positive.
The ten first Fibonacci numbers modulo 5:
> (map (lambda (n) (modular-fibonacci n 5)) (range 10)) (0 1 1 2 3 0 3 3 1 4)[procedure] (make-modular-fibonacci a b) -> (integer integer -> integer)
- a
- integer
- b
- integer
Like make-fibonacci, but makes a modular fibonacci sequence.
[procedure] (farey-sequence n) -> (list-of ratnum)- n
- integer
Returns a list of the numbers in the nth Farey sequence; n must be positive.
The nth Farey sequence is the sequence of all completely reduced rational numbers from 0 to 1 which denominators are less than or equal to n.
> (farey-sequence 1) (0 1) > (farey-sequence 2) (0 1/2 1) > (farey-sequence 3) (0 1/3 1/2 2/3 1)
Wikipedia: Farey Sequence
[procedure] (tangent-number n) -> integer- n
- integer
Returns the nth tangent number; n must be nonnegative.
> (tangent-number 1) 1 > (tangent-number 2) 0 > (tangent-number 3) 2
MathWorld: Tangent Number
Combinatorics
[procedure] (factorial n) -> integer- n
- integer
Returns the factorial of n, which must be nonnegative. The factorial of n is the number (* n (- n 1) (- n 2) ... 1).
> (factorial 3) 6 > (factorial 0) 1
Wikipedia: Factorial
[procedure] (binomial n k) -> integer- n
- integer
- k
- integer
Returns the number of ways to choose a set of k items from a set of n items; i.e. the order of the k items is not significant. Both arguments must be nonnegative.
When k > n, (binomial n k) = 0. Otherwise, (binomial n k) is equivalent to (/ (factorial n) (factorial k) (factorial (- n k))), but computed more quickly.
> (binomial 5 3)
10
Wikipedia: Binomial Coefficient
[procedure] (permutations n k) -> integer- n
- integer
- k
- integer
Returns the number of ways to choose a sequence of k items from a set of n items; i.e. the order of the k items is significant. Both arguments must be nonnegative.
When k > n, (permutations n k) = 0. Otherwise, (permutations n k) is equivalent to (/ (factorial n) (factorial (- n k))).
> (permutations 5 3)
60
Wikipedia: Permutations
[procedure] (multinomial n ks) -> integer- n
- integer
- ks
- (list-of integer)
A generalization of binomial to multiple sets of choices; e.g. (multinomial n (list k0 k1 k2)) is the number of ways to choose a set of k0 items, a set of k1 items, and a set of k2 items from a set of n items. All arguments must be nonnegative.
When (apply + ks) = n, this is equivalent to (apply / (factorial n) (map factorial ks)). Otherwise, multinomial returns 0.
> (multinomial 5 '(3 2)) 10 > (= (multinomial 8 '(5 3)) (binomial 8 5) (binomial 8 3)) #t > (multinomial 10 '(5 3 2)) 2520 > (multinomial 0 '()) 1 > (multinomial 4 '(1 1)) 0
Wikipedia: Multinomial Coefficient
[procedure] (partitions n) -> integer- n
- integer
Returns the number of partitions of n, which must be nonnegative. A partition of a positive integer n is a way of writing n as a sum of positive integers. The number 3 has the partitions (+ 1 1 1), (+ 1 2) and (+ 3).
> (partitions 3) 3 > (partitions 4) 5
Wikipedia: Partition
Polygonal numbers
[procedure] (triangle-number? n) -> boolean[procedure] (square-number? n) -> boolean
[procedure] (pentagonal-number? n) -> boolean
[procedure] (hexagonal-number? n) -> boolean
[procedure] (heptagonal-number? n) -> boolean
[procedure] (octagonal-number? n) -> boolean
- n
- integer
These functions check whether the input is a polygonal number of the types triangle, square, pentagonal, hexagonal, heptagonal and octogonal respectively.
Wikipedia: Polygonal Number
[procedure] (triangle-number n) -> boolean[procedure] (sqr n) -> boolean
[procedure] (pentagonal-number n) -> boolean
[procedure] (hexagonal-number n) -> boolean
[procedure] (heptagonal-number n) -> boolean
[procedure] (octagonal-number n) -> boolean
- n
- integer
These functions return the nth polygonal number of the corresponding type of polygonal number.
Fractions
[procedure] (mediant x y) -> ratnum- x
- ratnum
- y
- ratnum
Computes the mediant of the numbers x and y. The mediant of two fractions p/q and r/s in their lowest term is the number (p+r)/(q+s).
> (mediant 1/2 5/6)
3/4
Wikipedia: Mediant
The Quadratic Equation
[procedure] (quadratic-solutions a b c) -> (list-of number)a : number b : number c : number
Returns a list of all real solutions to the equation a x^2 + bx + c = 0 with real coefficients.
> (quadratic-solutions 1 0 -1) '(-1 1) > (quadratic-solutions 1 2 1) '(-1) > (quadratic-solutions 1 0 1) '()[procedure] (quadratic-integer-solutions a b c) -> (list-of integer)
- a
- number
- b
- number
- c
- number
Returns a list of all integer solutions to the equation a x^2 + bx + c = 0 with real coefficients.
> (quadratic-integer-solutions 1 0 -1) '(-1 1) > (quadratic-integer-solutions 1 0 -2) '()[procedure] (quadratic-natural-solutions a b c) -> (list-of integer)
- a
- number
- b
- number
- c
- number
Returns a list of all natural solutions to the equation a x^2 + bx + c = 0 with real coefficients.
> (quadratic-natural-solutions 1 0 -1) '(1) > (quadratic-natural-solutions 1 0 -2) '()[procedure] (complex-quadratic-solutions a b c) -> (list-of number)
- a
- number
- b
- number
- c
- number
Returns a list of all complex solutions to the equation a x^2 + bx + c = 0. This function allows complex coeffecients.
> (complex-quadratic-solutions 1 0 1) (0-1i 0+1i) > (complex-quadratic-solutions 1 0 (sqrt -1)) (-0.7071067811865476+0.7071067811865475i 0.7071067811865476-0.7071067811865475i) > (complex-quadratic-solutions 1 0 1) (0-1i 0+1i)
The group Zn and Primitive Roots
The numbers 0, 1, ..., n-1 with addition and multiplication modulo n is a ring called Zn.
The group of units in Zn with respect to multiplication modulo n is called Un.
The order of an element x in Un is the least k>0 such that x^k=1 mod n.
A generator the group Un is called a primitive root modulo n. Note that g is a primitive root if and only if order(g)=totient(n). A group with a generator is called cyclic.
Wikipedia: The Group Zn
[procedure] (unit-group n) -> (list-of integer)- n
- integer
Returns a list of all elements of Un, the unit group modulo n. The modulus n must be positive.
> (unit-group 5) (1 2 3 4) > (unit-group 6) (1 5)[procedure] (unit-group-order x n) -> integer
- x
- integer
- n
- integer
Returns the order of x in the group Un; both arguments must be positive. If x and n are not coprime, (unit-group-order x n) raises an error.
> (unit-group-order 2 5) 4 > (unit-group-order 2 6) Error: (unit-group-order) expected coprime arguments; given 2 and 6[procedure] (unit-group-orders n) -> (list-of positive-integer)
- n
- integer
Returns a list (list (unit-group-order x0 n) (unit-group-order x1 n) ...) where x0, x1, ... are the elements of Un. The modulus n must be positive.
> (unit-group-orders 5) (1 4 4 2) > (map (cut unit-group-order <> 5) (unit-group 5)) (1 4 4 2)[procedure] (primitive-root? x n) -> boolean
- x
- integer
- n
- integer
Returns #t if the element x in Un is a primitive root modulo n, otherwise #f is returned. An error is signaled if x is not a member of Un. Both arguments must be positive.
> (primitive-root? 1 5) #f > (primitive-root? 2 5) #t > (primitive-root? 5 5) Error: (primitive-root?) expected coprime arguments; given 5 and 5[procedure] (exists-primitive-root? n) -> boolean
- n
- integer
Returns #t if the group Un has a primitive root (i.e. it is cyclic), otherwise #f is returned. In other words, #t is returned if n is one of 1, 2, 4, p^e, 2*p^e where p is an odd prime, and #f otherwise. The modulus n must be positive.
> (exists-primitive-root? 5) #t > (exists-primitive-root? 6) #t > (exists-primitive-root? 12) #f[procedure] (primitive-root n) -> (or integer false)
Returns a primitive root of Un if one exists, otherwise #f is returned. The modulus n must be positive.
> (primitive-root 5) 2 > (primitive-root 6) 5[procedure] (primitive-roots n) -> (list-of integer)
- n
- integer
Returns a list of all primitive roots of {Un}. The modulus n must be positive.
> (primitive-roots 3) (2) > (primitive-roots 5) (2 3) > (primitive-roots 6) (5)
Original documentation
https://docs.racket-lang.org/math/
Author
Neil Toronto and Jens Axel Søgaard for Racket
Maintainer
Repository
https://git.sr.ht/~dieggsy/chicken-math
License
GPL-3.0
Version History
- 0.3.4
- Reflect upstream changes
- 0.3.3
- Remove -strict-types from build for time being
- 0.3.2
- Correct types and types files
- 0.3.1
- Ensure to export all api procedures, correct module dependencies for build
- 0.3.0
- Finish (math base) and (math flonum), bug and typo fixes, credit original authors
- 0.2.3
- Fix broken .egg file
- 0.2.2
- Re-organize internals, add (math base constants)
- 0.2.1
- Minor bug fixes
- 0.2.0
- Update (math number-theory quadratic) to reflect upstream
- 0.1.0
- Initial release